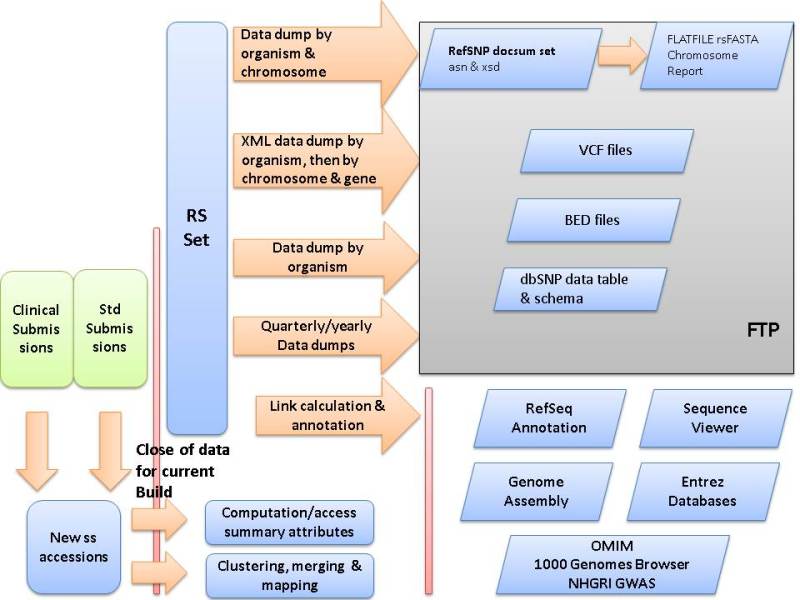
From: The Database of Short Genetic Variation (dbSNP)

The NCBI Handbook [Internet]. 2nd edition.
Bethesda (MD): National Center for Biotechnology Information (US); 2013-.
NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.